
AI 관련 공부를 하다보면 논문을 기반하여 모델을 구현하는 사람들이 많다.
코드 한줄 없는 논문을 보고 어떻게 코드로 구현하는지 한번 알아보자
※ 처음부터 독학하면서 얻은 경험을 기술한 것이기에 과정에 있어 오답이 특히 많을 수 있습니다.
오늘 구현해볼 논문은 Google이 발표한 MobileNet V1입니다.
그리고 따라 구현하려면 최소한 CNN(Convolutional Neural Network)에 대한 지식은 있어야 이해 할 수 있습니다.
또한 구현을 위해 사용하는 프레임 워크가 PyTorch 이므로 이에 대한 기본 지식이 있어야 합니다.
논문 주소 : https://arxiv.org/pdf/1704.04861
사용하는 프레임워크 : PyTorch
1. 모델의 구조 해석
해당 논문에서는 3.3의 Table. 1을 보면 아주 친절하게 MobileNet Body Architecture라고 정의를 해줬습니다
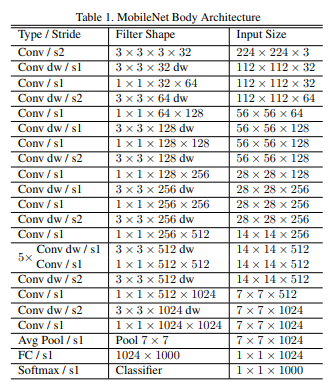
위에서부터 차근차근 블록을 작성한 다음 묶어주면 끝입니다.
데이터에 대한 설명을 보자면,
Type/Stride : 블록의 타입(Conv인지 Depthwise Conv인지 등), Stride(한번에 이동할 칸 수)의 수를 몇으로 할지 지정합니다.
예를 들어 맨 처음의 Conv / s2는 Conv 블록에 Stride의 값을 2로 설정하겠다는 뜻입니다.
Filter Shape : 블록에 들어가는 필터에 대한 구조를 의미합니다.
예를 들어 맨 처음의 3 x 3 x 3 x 32에서,
32(맨 마지막 값[channel])는 output_channels값을 의미
3 x 3(앞에서 부터 2개[kernel]) 은 커널(kernel)의 크기를 의미
※ CNN을 아신다면 k = 2p + 1공식에 따라 p(padding)값도 자연스레 아실 수 있겠죠?
Input Size : 블록에 들어가는 데이터 구조를 의미합니다.
예를 들어 맨 처음의 224 x 224 x 3에서,
3(맨 마지막 값[channel])이 input_channels 값을 의미합니다.
예시로 맨 처음의 데이터를 종합하면
input_channels = 3
output_channels = 32
kernel = 3
padding = 1
stride = 2
라는 정보를 확인 할 수 있습니다.
그러면 pytorch의 nn.Conv2d(MobileNet은 2차원 Vision모델이니까 Conv2d를 사용)에 접목하면
import torch.nn as nn
nn.Conv2d(
in_channels=3,
out_channels=32,
kernel_size=3,
stride=2,
padding=1,
)이렇게 표현 할 수 있습니다.
2. 세부 주의사항
이렇게만 하면 끝날거 같지만 주의해야할 점이 있습니다.
바로 논문 3.2 에서는 이런 내용이 있습니다.
All layers are followed by a batchnorm [13] and ReLU nonlinearity with the exception of the final fully connected layer which has no nonlinearity and feeds into a softmax layer for classification
이게 무슨 말이냐 하면, 모든 레이어들은 그 뒤에 batchnorm 그리고 ReLU 가 붙어야 한다는 점입니다.
이 말인 즉슨, 위에서 말한 nn.Conv2d만 바로 사용하면 원하는 결과가 안나온다는 점 입니다.
그렇기에 Conv를 함수형으로 간단하게 포장을 하려 합니다.
import torch.nn as nn
def conv(
in_channels: int, out_channels: int, kernel_size: int, stride: int, padding: int
):
return nn.Sequential(
nn.Conv2d(
in_channels=in_channels,
out_channels=out_channels,
kernel_size=kernel_size,
stride=stride,
padding=padding,
bias=False, # 편향 가중치 사용 여부. 뒤의 BatchNorm 에서 편향을 사용하기에 중복이라서 비활성화
),
nn.BatchNorm2d(num_features=out_channels),
nn.ReLU(inplace=True),
)
이렇게 수정하면 Conv 레이어마다 batchnorm, relu를 일일히 호출할 필요가 없겠지요?
3. 레이어 결합
자 이렇게 기본적으로 구조를 파악하고 레이어(블록)을 구현하는 방법도 알았으니 쭉 작성하면 끝입니다.
단, 우리는 학습을 해야하는데 이때 역전파 통해 하려면 그걸 코드로 직접 구현하려면 너무 힘들기에 Pytorch에서는 forward를 통해 모드 설정만 하면 쉽게 할 수 있도록 했습니다.
단, 모델이 이런 구조로 엮여있다 라는걸 알려줘야 하기에 이를 nn.Sequential 혹은 nn.ModuleList로 묶어야 합니다.
오늘은 간단한 구조이기에 nn.Sequential로 묶도록 하겠습니다.
import torch.nn as nn
class MobileNetV1(nn.Module):
def __init__(self, num_classes: int):
super().__init__()
self.model = nn.Sequential(
conv(3, 32, 3, 2, 1), # Conv / s2 3 × 3 × 3 × 32 224 × 224 × 3
conv_dw(32, 32, 3, 1, 1), # Conv dw / s1 3 × 3 × 32 dw 112 × 112 × 32
conv(32, 64, 1, 1, 0), # Conv / s1 1 × 1 × 32 × 64 112 × 112 × 32
)
def forward(self, x):
x = self.model(x)
return x
이렇게만 하면 모델이 묶였습니다. 간단하지요?
그럼 이제 모델 전체 코드를 드리겠습니다.
4. 전체 코드
import torch.nn as nn
# MobileNet V1 논문 URL : https://arxiv.org/pdf/1704.04861
# 설명하는 함수입니다. 실제 로직은 아닙니다.
def explain_to_conv2d_and_avgpool():
# Conv / s2 3 × 3 × 3 × 32 224 × 224 × 3
# 입력 크기 : 224 x 224 x 3 -> (H, W, C)
# 커널 크기 : 3 x 3 ('3 x 3' x 3 x 32) -> 2D 필터 크기
# 입력 채널 : 3 (224 x 224 x '3')
# 출력 채널 : 32 (3 x 3 x 3 x '32')
# stride : 2 (s'2')
# padding : k = 2p + 1 -> 3 = 2p + 1 -> p = 1
# 출력 채널 공식 : Hout = (Hin - K + 2p) / S + 1
conv_2d_1 = nn.Conv2d(
in_channels=3, out_channels=32, kernel_size=3, stride=2, padding=1
)
# Conv dw / s1 3 × 3 × 32 dw 112 × 112 × 32
# 입력 크기 : 112 x 112 x 32 -> (H, W, C)
# 커널 크기 : 3 x 3 ('3 x 3' x 32) -> 2D 필터 크기
# 입력 채널 : 3 (112 x 112 x '32')
# 출력 채널 : 32 (3 x 3 x '32')
# stride : 2 (s'1')
# 타입 groups 값 의미
# 일반 Conv 1 모든 채널이 서로 연결됨
# Depthwise Conv groups = in_channels 채널별로 독립적인 필터
# Grouped Conv 1 < groups < in_channels 일부 채널끼리만 연결
conv_depth_wise_2 = nn.Conv2d(
in_channels=32,
out_channels=32,
kernel_size=3,
stride=1,
padding=1,
groups=32, # depth wise의 경우, in channels와 동일 값
)
# Conv / s1 1 × 1 × 32 × 64 112 × 112 × 32
# padding : k = 2p + 1 -> 1 = 2p + 1 -> p = 0
conv_2d_3 = nn.Conv2d(
in_channels=32, out_channels=64, kernel_size=1, stride=1, padding=0
)
# Avg Pool / s1 Pool 7 × 7 7 × 7 × 1024
# 여기선 feature map을 추출하는게 아니기에 padding값을 0으로 설정
avg_pool = nn.AvgPool2d(kernel_size=7, stride=1, padding=0)
# 만약 입력 값이 7 x 7이 아닐 경우 대비, 자동으로 입력값 크기 상관없이 1x1로 결과물을 해주는 함수(일반적)
avg_pool_adaptive = nn.AdaptiveAvgPool2d(output_size=(1, 1))
def conv(
in_channels: int, out_channels: int, kernel_size: int, stride: int, padding: int
):
return nn.Sequential(
nn.Conv2d(
in_channels=in_channels,
out_channels=out_channels,
kernel_size=kernel_size,
stride=stride,
padding=padding,
bias=False, # 편향 가중치 사용 여부. 뒤의 BatchNorm 에서 편향을 사용하기에 중복이라서 비활성화
),
nn.BatchNorm2d(num_features=out_channels),
nn.ReLU6(inplace=True),
)
# Depthwise Conv
def conv_dw(
in_channels: int, out_channels: int, kernel_size: int, stride: int, padding: int
):
return nn.Sequential(
nn.Conv2d(
in_channels=in_channels,
out_channels=out_channels,
kernel_size=kernel_size,
stride=stride,
padding=padding,
groups=in_channels,
bias=False, # 편향 가중치 사용 여부. 뒤의 BatchNorm 에서 편향을 사용하기에 중복이라서 비활성화
),
nn.BatchNorm2d(num_features=out_channels),
nn.ReLU6(inplace=True),
)
class MobileNetV1(nn.Module):
def __init__(self, num_classes: int):
super().__init__()
self.model = nn.Sequential(
conv(3, 32, 3, 2, 1), # Conv / s2 3 × 3 × 3 × 32 224 × 224 × 3
conv_dw(32, 32, 3, 1, 1), # Conv dw / s1 3 × 3 × 32 dw 112 × 112 × 32
conv(32, 64, 1, 1, 0), # Conv / s1 1 × 1 × 32 × 64 112 × 112 × 32
conv_dw(64, 64, 3, 2, 1), # Conv dw / s2 3 × 3 × 64 dw 112 × 112 × 64
conv(64, 128, 1, 1, 0), # Conv / s1 1 × 1 × 64 × 128 56 × 56 × 64
conv_dw(128, 128, 3, 1, 1), # Conv dw / s1 3 × 3 × 128 dw 56 × 56 × 128
conv(128, 128, 1, 1, 0), # Conv / s1 1 × 1 × 128 × 128 56 × 56 × 128
conv_dw(128, 128, 3, 2, 1), # Conv dw / s2 3 × 3 × 128 dw 56 × 56 × 128
conv(128, 256, 1, 1, 0), # Conv / s1 1 × 1 × 128 × 256 28 × 28 × 128
conv_dw(256, 256, 3, 1, 1), # Conv dw / s1 3 × 3 × 256 dw 28 × 28 × 256
conv(256, 256, 1, 1, 0), # Conv / s1 1 × 1 × 256 × 256 28 × 28 × 256
conv_dw(256, 256, 3, 2, 1), # Conv dw / s2 3 × 3 × 256 dw 28 × 28 × 256
conv(256, 512, 1, 1, 0), # Conv / s1 1 × 1 × 256 × 512 14 × 14 × 256
# 5×
*[
layer
for _ in range(5)
for layer in (
conv_dw(512, 512, 3, 1, 1),
conv(512, 512, 1, 1, 0),
)
],
conv_dw(512, 512, 3, 2, 1), # Conv dw / s2 3 × 3 × 512 dw 14 × 14 × 512
conv(512, 1024, 1, 1, 0), # Conv / s1 1 × 1 × 512 × 1024 7 × 7 × 512
conv_dw(1024, 1024, 3, 2, 1), # Conv dw / s2 3 × 3 × 1024 dw 7 × 7 × 1024
conv(1024, 1024, 1, 1, 0), # Conv / s1 1 × 1 × 1024 × 1024 7 × 7 × 1024
# Avg Pool / s1 Pool 7 × 7 7 × 7 × 1024
# 여기선 feature map을 추출하는게 아니기에 padding값을 0으로 설정
# nn.AvgPool2d(kernel_size=7, stride=1, padding=0)
nn.AdaptiveAvgPool2d(output_size=(1, 1)) # 위 방식이 논문에 더 가깝지만 이 방식이 편리합니다.
)
# FC / s1 1024 × 1000 1 × 1 × 1024
# out_feature는 class의 갯수만큼
self.fc = nn.Linear(in_features=1024, out_features=num_classes)
def forward(self, x):
x = self.model(x)
x = x.view(
-1, 1024
) # -1 : batch 크기 자동화 설정, 1024 : feature channel를 평탄화 하는 사이즈
x = self.fc(x)
return x
학습을 하는 코드는 다음에 포스팅 해보도록 하겠습니다.
질문 혹은 틀린 점 알려주시는 건 언제든 환영입니다.
'개발잡담 > AI' 카테고리의 다른 글
| MNIST 데이터로 VLM 만들어보기 (Feat. HyperClovaX) - LLM 결합, 학습 & 추론 (0) | 2026.01.09 |
|---|---|
| MNIST 데이터로 VLM 만들어보기 (Feat. HyperClovaX) - ViT Encoder (2) | 2026.01.08 |
| LLaVA에 대해 알아보자 - Predict (0) | 2025.12.16 |
| PYTORCH 가중치 파일을 ONNX로 변환하기 (Feat. YOLO) (0) | 2025.12.10 |